Mysql知识点总结
1、undo、redolog
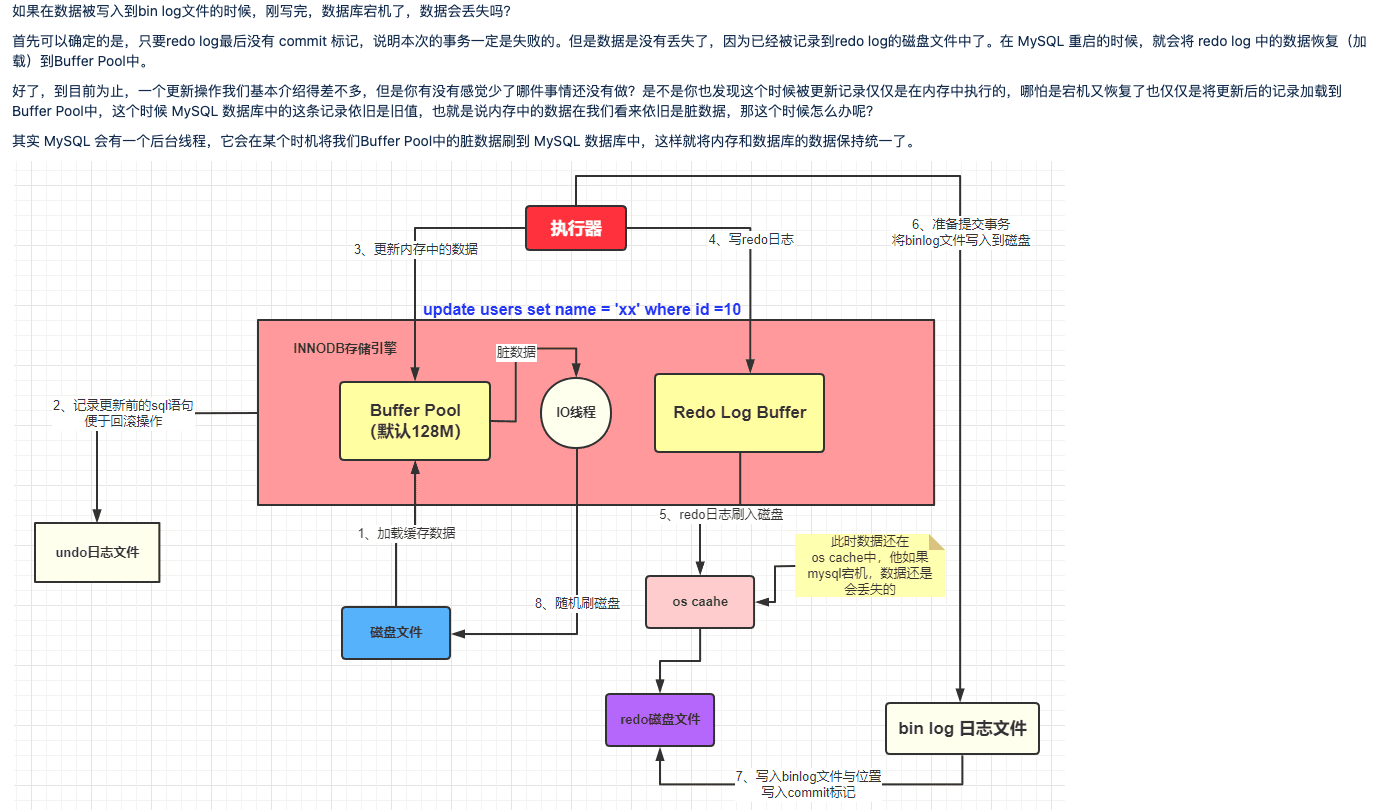
截至目前,我们应该都熟悉了 MySQL 的执行器调用存储引擎是怎么将一条 SQL 加载到缓冲池和记录哪些日志的,流程如下:
- 准备更新一条 SQL 语句
- MySQL(innodb)会先去缓冲池(BufferPool)中去查找这条数据,没找到就会去磁盘中查找,如果查找到就会将这条数据加载到缓冲池(BufferPool)中
- 在加载到 Buffer Pool 的同时,会将这条数据的原始记录保存到 undo 日志文件中
- innodb 会在 Buffer Pool 中执行更新操作
- 更新后的数据会记录在 redo log buffer 中
上面说的步骤都是在正常情况下的操作,但是程序的设计和优化并不仅是为了这些正常情况而去做的,也是为了那些临界区和极端情况下出现的问题去优化设计的
这个时候如果服务器宕机了,那么缓存中的数据还是丢失了。真烦,竟然数据总是丢失,那能不能不要放在内存中,直接保存到磁盘呢?很显然不行,因为在上面也已经介绍了,在内存中的操作目的是为了提高效率。
此时,如果 MySQL 真的宕机了,那么没关系的,因为 MySQL 会认为本次事务是失败的,所以数据依旧是更新前的样子,并不会有任何的影响。
好了,语句也更新好了那么需要将更新的值提交啊,也就是需要提交本次的事务了,因为只要事务成功提交了,才会将最后的变更保存到数据库,在提交事务前仍然会具有相关的其他操作
将 redo Log Buffer 中的数据持久化到磁盘中,就是将 redo log buffer 中的数据写入到 redo log 磁盘文件中,一般情况下,redo log Buffer 数据写入磁盘的策略是立即刷入磁盘(具体策略情况在下面小总结出会详细介绍),上图
如果 redo log Buffer 刷入磁盘后,数据库服务器宕机了,那我们更新的数据怎么办?此时数据是在内存中,数据岂不是丢失了?不,这次数据就不会丢失了,因为 redo log buffer 中的数据已经被写入到磁盘了,已经被持久化了,就算数据库宕机了,在下次重启的时候 MySQL 也会将 redo 日志文件内容恢复到 Buffer Pool 中(这边我的理解是和 Redis 的持久化机制是差不多的,在 Redis 启动的时候会检查 rdb 或者是 aof 或者是两者都检查,根据持久化的文件来将数据恢复到内存中)
到此为止,从执行器开始调用存储引擎接口做了哪些事情呢?
- 准备更新一条 SQL 语句
- MySQL(innodb)会先去缓冲池(BufferPool)中去查找这条数据,没找到就会去磁盘中查找,如果查找到就会将这条数据加载到缓冲池(BufferPool)中
- 在加载到 Buffer Pool 的同时,会将这条数据的原始记录保存到 undo 日志文件中
- innodb 会在 Buffer Pool 中执行更新操作
- 更新后的数据会记录在 redo log buffer 中
- MySQL 提交事务的时候,会将 redo log buffer 中的数据写入到 redo 日志文件中 刷磁盘可以通过 innodb_flush_log_at_trx_commit 参数来设置
- 值为 0 表示不刷入磁盘
- 值为 1 表示立即刷入磁盘
- 值为 2 表示先刷到 os cache
- myslq 重启的时候会将 redo 日志恢复到缓冲池中
截止到目前位置,MySQL 的执行器调用存储引擎的接口去执行【执行计划】提供的 SQL 的时候 InnoDB 做了哪些事情也就基本差不多了,但是这还没完。下面还需要介绍下 MySQL 级别的日志文件 bin log。
如果在数据被写入到bin log文件的时候,刚写完,数据库宕机了,数据会丢失吗?
首先可以确定的是,只要redo log最后没有 commit 标记,说明本次的事务一定是失败的。但是数据是没有丢失了,因为已经被记录到redo log的磁盘文件中了。在 MySQL 重启的时候,就会将 redo log 中的数据恢复(加载)到Buffer Pool中。
好了,到目前为止,一个更新操作我们基本介绍得差不多,但是你有没有感觉少了哪件事情还没有做?是不是你也发现这个时候被更新记录仅仅是在内存中执行的,哪怕是宕机又恢复了也仅仅是将更新后的记录加载到Buffer Pool中,这个时候 MySQL 数据库中的这条记录依旧是旧值,也就是说内存中的数据在我们看来依旧是脏数据,那这个时候怎么办呢?
其实 MySQL 会有一个后台线程,它会在某个时机将我们Buffer Pool中的脏数据刷到 MySQL 数据库中,这样就将内存和数据库的数据保持统一了。
2、flush链表、free链表、lru链表
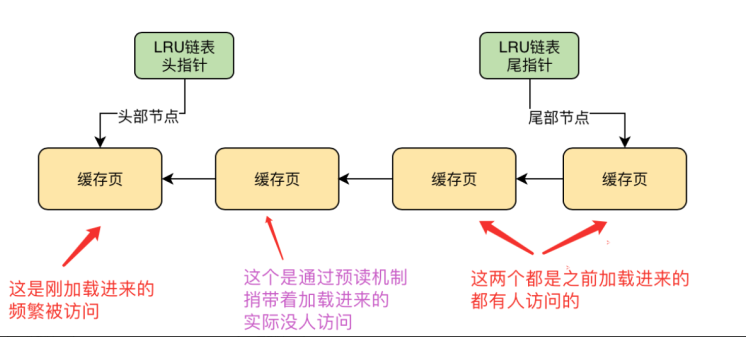
db刚启动的时候lru是空的,全都是free链表,然后从磁盘读取数据页加入到lru链表,如果有free链表就直接把free加入lru, 如果没有free的链表,就从lru的尾指针淘汰数据页,在冷数据区的开头处新增节点。
冷数据1/3起始处, 默认冷数据37%。 为了防止预读机制,全表扫描。把过多的热数据直接排除内存。mysql设定了一个参数innodb_old_blocks_time参数 默认1s,在1s之后访问这个缓存页才会挪动到热数据区域的链表头。
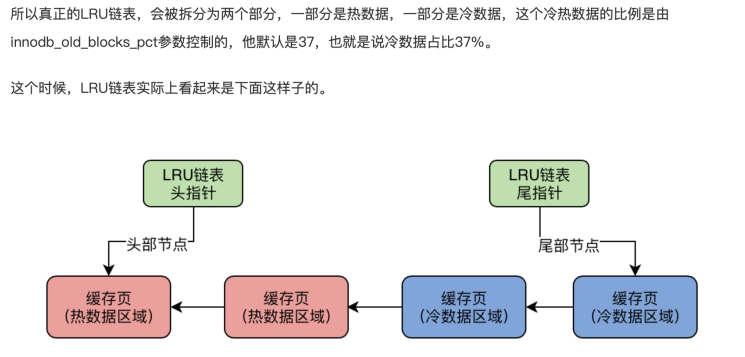
flush链表是管理内存中有修改的需要刷盘的脏数据。在LRU列表中的页被修改后,称该页为脏页(dirty page),即缓冲池中的页和磁盘上的页的数据产生了不一致。这时数据库会通过CHECKPOINT机制将脏页刷新回磁盘,而Flush列表中的页即为脏页列表。需要注意的是,脏页既存在于LRU列表中,也存在于Flush列表中。LRU列表用来管理缓冲池中页的可用性,Flush列表用来管理将页刷新回磁盘,二者互不影响。
3、binlog
binlog_format是一个非常重要的参数,决定了记录二进制日志的格式:
可选值有:
- STATEMENT
记录SQL语句。日志文件小,节约IO,但是对一些系统函数不能准确复制或不能复制,如now()、uuid()等。
5.7.7之前日志默认格式是STATEMENT。
- ROW
记录表的行更改情况,可以为数据库的恢复、复制带来更好的可靠性,但是二进制文件的大小相较于STATEMENT会有所增加。
Mysql8日志默认格式是ROW。
注意:如果用canal做数据同步ROW格式是必须的
https://github.com/alibaba/canal/wiki/QuickStart

- MIXED
STATEMENT和ROW模式的混合。默认采用STATEMENT格式进行二进制日志文件的记录,但是在一些情况下会使用ROW格式。
业内目前推荐使用的是ROW模式,准确性高,虽然说文件大,但是现在有SSD和万兆光纤网络,这些磁盘IO和网络IO都是可以接受的。
show binary logs --或者show master logs命令查看二进制日志的文件列表
show binlog events in 'mysql-bin.000116' -- 命令查看binlog的事件列表,我们看最新也就是最后一个binlog文件mysql-bin.000116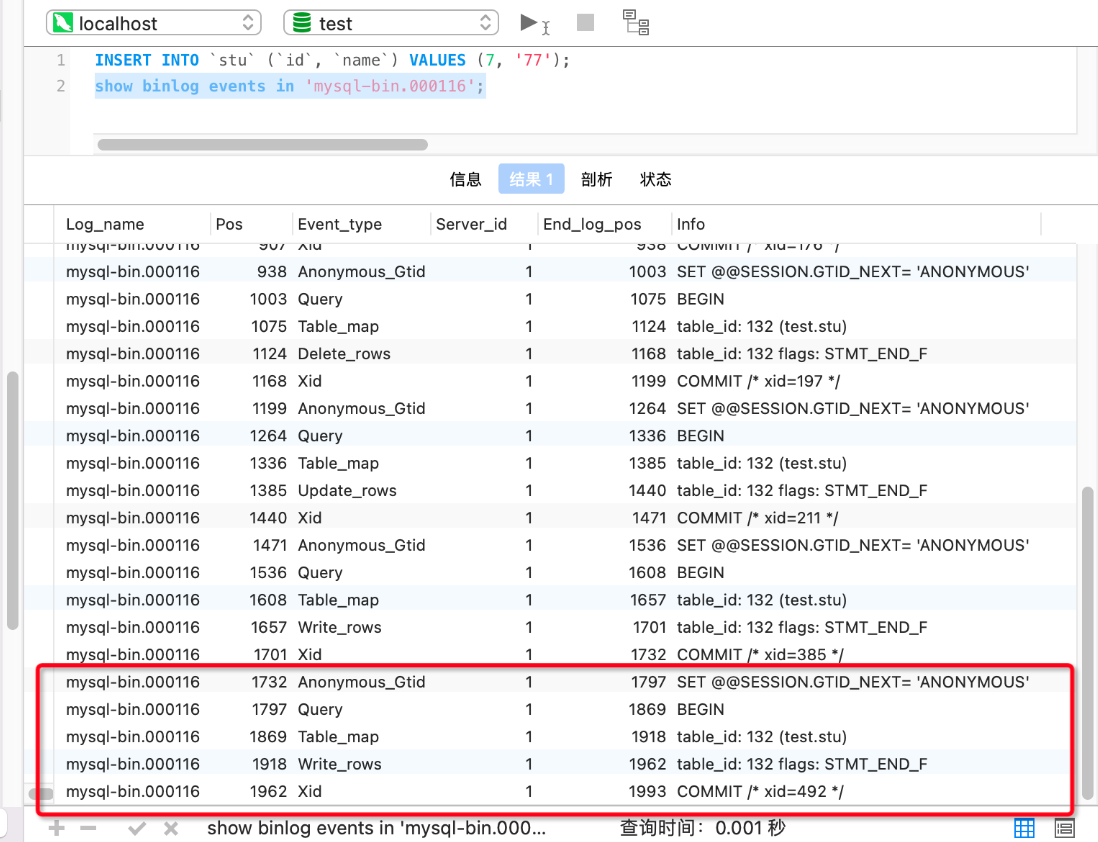
4、mysql架构
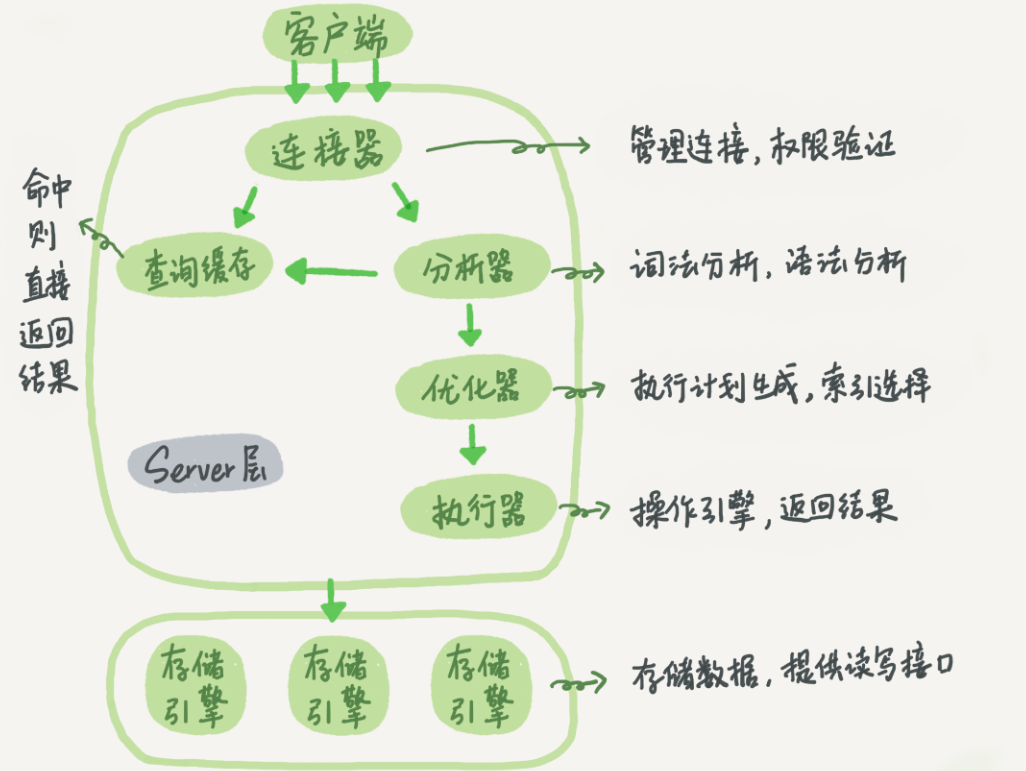
1、
WAL的全称是Write-Ahead Logging预写日志,对于mysql就是先写日志,后写磁盘。
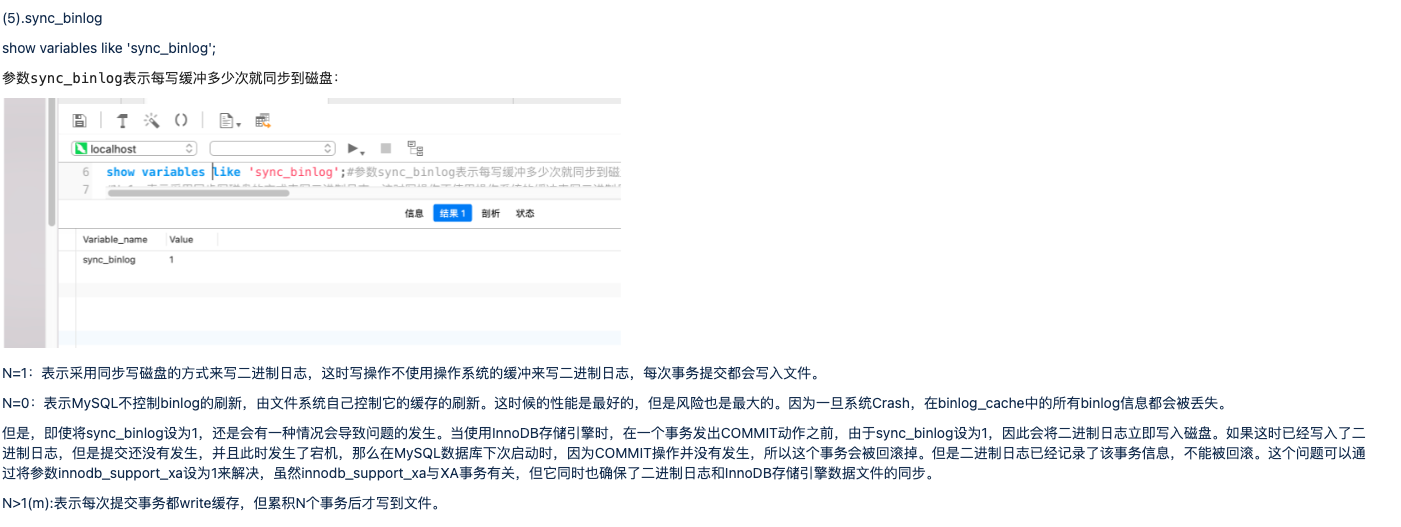
写磁盘慢,写日志快,写完日志系统不忙的时候再写磁盘。和我们代码review的时候,会上先记录问题,会下再改代码是一个意思。 [因为可能一个事务需要修改多张表多条记录,每个记录在不同的数据页中,一次事务提交多次随机寻址 对IO的压力太大,就在内存里面提交事务,然后有个后台线程定时异步更新磁盘。][内存操作数据+Write-Ahead Log的这种思想非常普遍, LSM树的时候,还会再次提到这个思想。在多备份一致性中,复制状态机的模型也是基于此]
在InnoDB中,不光事务修改的数据库表数据是异步刷盘的,连Redo Log的写入本身也是异步的, 通过innodb_flush_log_at_trx_commit参数控制redo log刷盘的策略。
0:每秒刷一次磁盘,把Redo Log Buffer中的数据刷到Redo Log (默认为0)。
1:每提交一个事务,就刷一次磁盘(这个最安全)。
2:不刷盘。然后根据参数innodb_flush_log_at_timeout设置的值决定刷盘频率。很显然,该参数设置为0或者2都可能丢失数据。设置为1最安全,但性能最差。InnoDB设置此参数,也是为了让应用在数据安全性和性能之间做一个权衡。
https://blog.csdn.net/u010711495/article/details/118453965
2、
CrashSafe指MySQL服务器宕机重启后,能够保证:
所有已经提交的事务的数据仍然存在。
所有没有提交的事务的数据自动回滚。
## 1.什么是redolog
## 2.为什么需要redolog
## 3.什么是两阶段提交
## 4.redolog和binlog区别
# 三、undolog
# 四、主从复制
[24讲MySQL是怎么保证主备一致的.html](http://ydwiki.yidian-inc.com/download/attachments/109948320/24%E8%AE%B2MySQL%E6%98%AF%E6%80%8E%E4%B9%88%E4%BF%9D%E8%AF%81%E4%B8%BB%E5%A4%87%E4%B8%80%E8%87%B4%E7%9A%84.html?version=1&modificationDate=1686035896000&api=v2)5、SQL解析器和优化器及执行
SQL解析器、优化器和执行引擎是数据库管理系统(DBMS)中的关键组件,它们共同工作以处理和执行SQL查询。下面是这三个组件的简要说明:
SQL解析器(Parser):
SQL解析器负责将用户输入的SQL查询转换为内部数据结构,通常称为解析树或查询树。解析器执行以下主要任务:
a. 语法分析:检查SQL查询是否遵循正确的语法规则。将SQL语句转换为一系列词法单元,例如关键字、标识符、运算符和常量等。
SQL解析器进行词法分析的过程通常如下:
- 读取SQL语句中的字符流。
- 逐个字符地处理字符流,将其转换成一个个词法单元。
- 识别关键字、标识符、运算符和常量等词法单元,并将它们分类。
- 对于标识符,还需要进行一些额外的处理,例如检查是否为表名或列名等。
- 将处理后的词法单元组成一个有序的词法单元序列,供语法分析器进一步处理。
SQL解析器通常会使用正则表达式、有限状态自动机等技术来进行词法分析。
b. 语义分析:验证查询中引用的表、列和其他对象是否存在,并检查用户是否具有执行查询所需的权限。
c. 构建查询树:将SQL查询转换为内部数据结构,以便进行进一步处理。
SQL优化器(Optimizer):
SQL优化器负责找到执行给定查询的最有效方法,即选择最佳的执行计划。优化器考虑多种可能的执行计划,并基于成本模型、索引、表的统计信息和其他因素选择一个计划。
SQL解析器进行优化器处理的过程通常如下:
- 生成语法树后,优化器会对SQL语句进行分析,确定最佳的执行计划。
- 优化器会根据查询条件、索引、表大小等因素选择最优的执行计划。
- 优化器会尝试使用索引来加速查询,如果没有合适的索引,则会考虑创建新的索引。
- 优化器还会考虑使用连接方式、子查询、分组、排序等技术来优化查询效率。
- 最终,优化器会生成一个执行计划,该执行计划是一个有序的操作序列,用于执行SQL查询并返回结果。
SQL解析器通常会使用代价估算模型、统计信息等技术来进行优化器处理。
主要任务包括:
a. 查询重写:对查询进行变换,以便更有效地执行。例如,消除子查询,将它们转换为连接操作。
b. 选择访问路径:确定访问表和索引的最佳方法。
c. 连接顺序和方法:确定连接表的顺序和使用的连接算法(如嵌套循环连接、散列连接或合并连接)。
SQL执行引擎(Execution Engine):
SQL执行引擎是SQL查询的核心组件,它负责将解析器生成的查询计划转换为可以在计算机上执行的指令。SQL执行引擎还负责查询优化,以便在最短时间内返回结果。在执行查询时,SQL执行引擎会读取数据存储,并将结果返回给用户。
SQL执行引擎负责根据优化器选择的执行计划实际执行查询。执行引擎处理以下任务:
a. 执行操作:按照执行计划中的操作顺序(如扫描表、过滤行、连接表等)执行查询。
b. 内存管理:分配和管理查询执行过程中所需的内存资源。
c. 并发控制:协调多个并发查询之间的资源共享,确保数据的一致性和隔离性。
这三个组件共同确保数据库能够高效、准确地处理和执行用户提交的SQL查询。
sql(结构化查询语言)的详细执行过程,SQL是一种用于管理关系型数据库的语言。在执行SQL查询时,数据库管理系统(DBMS)会按照以下步骤进行:
语法分析:DBMS会检查查询语句是否符合SQL语法规范。
语义分析:DBMS会检查查询语句是否符合数据库中表和列的定义,并进行必要的类型转换。
查询优化:DBMS会根据查询的复杂度和表之间的关系来决定最优的查询方式,以提高查询效率。
执行计划生成:DBMS会生成一个执行计划,该计划包括了查询的具体执行步骤,如何访问表和使用索引等。
执行查询:DBMS会按照执行计划中定义的步骤执行查询,并返回结果集。
其中,查询优化和执行计划生成是SQL执行过程中最重要的步骤之一。在查询优化中,DBMS使用各种算法和技术来确定最佳查询方式,例如索引、连接类型、排序等。在执行计划生成中,DBMS会根据查询优化的结果生成一组指令,这些指令将被用于实际执行查询。



